
Tarantino Log of Deaths and Swears (2023 Updated, New Categories
Концепция
Я выбрала табличный датасет «Tarantino Log of Deaths and Swears (2023 Updated, New Categories)» в формате CSV. В нём по фильмам Квентина Тарантино отмечены события двух типов: ругательства (word) и смерти (death), а также время появления события в фильме и категория ругательства.
Фильмы Тарантино часто обсуждают именно из-за «языка» и уровня насилия. Этот датасет позволяет проверить стереотипы количественно: не просто сказать «там много мата и смертей», а сравнить фильмы между собой, измерить плотность событий и увидеть динамику по ходу фильма. Ценность данных в том, что они событийные и дают возможность анализировать не только «сколько», но и «когда».
Визуальный стиль
Выбор цветовой палитры был основан на фильмах Квентина Тарантина

Анализ данных
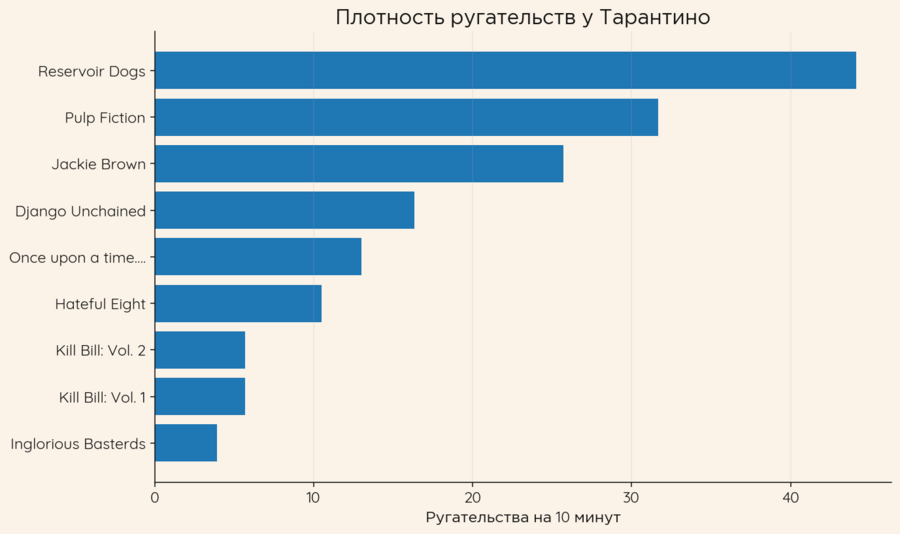
Визуализация данных
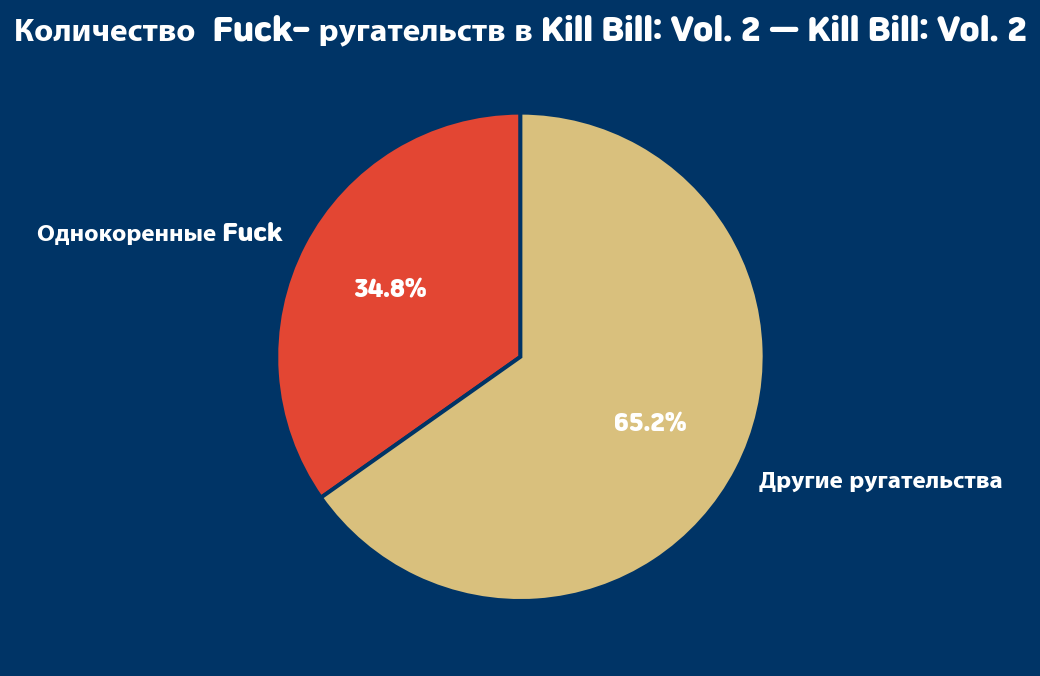
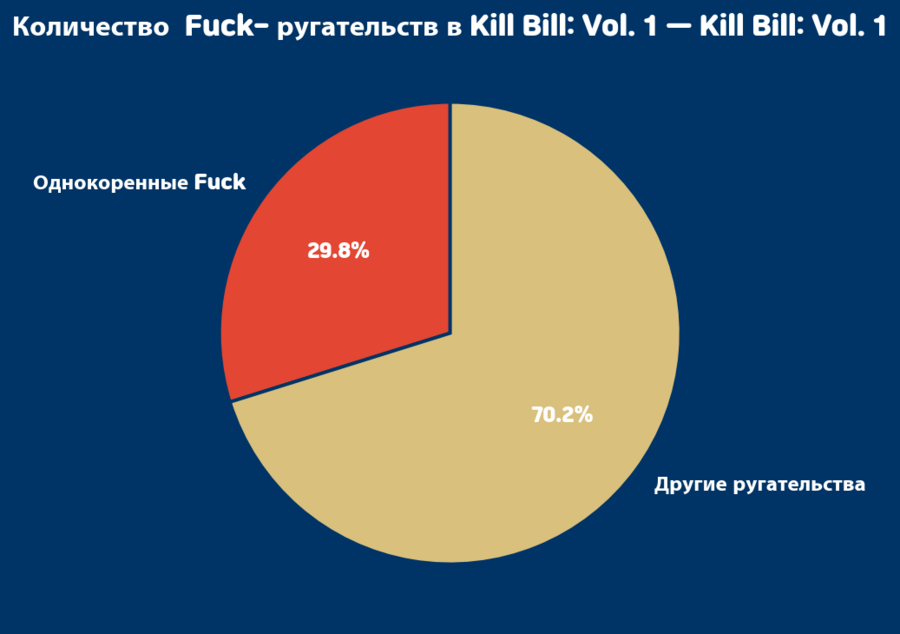
Данные я брала с Kaggle https://www.kaggle.com/datasets/bayesfan/updated-2023-tarantino-deathsswearwords Использовала нейросеть ChatGPT для объяснения и исправления ошибок в коде. https://chatgpt.com/



