
Анализ скорости публичных высказываний за последние 70 лет
Введение
В данном проекте исследуется, как менялась скорость речи в публичных высказываниях на протяжении второй половины XX и начала XXI века. Скорость речи рассматривается как количественный показатель, отражающий ритм времени, медиасреду и особенности публичной коммуникации.
Меня заинтересовал вопрос: можно ли увидеть устойчивый тренд ускорения речи со временем и зависит ли темп речи от формата высказывания. Проект выполнен в формате исследовательской визуализации данных с акцентом на интерпретацию и объяснение наблюдаемых закономерностей.
Данные
Для анализа использован табличный датасет, содержащий информацию о скорости речи в публичных высказываниях. В качестве основной метрики используется показатель words per minute (WPM) — количество слов, произнесённых за одну минуту.
Датасет включает следующие параметры: год высказывания, формат речи (лекция, интервью, публичное выступление), скорость речи (WPM).
Анализ данных выполнялся в среде Google Colab с использованием библиотеки Pandas.
Этапы работы
1. Формирование табличного датасета
2. Очистка данных и удаление нереалистичных значений
3. Группировка данных по годам и десятилетиям
4. Расчёт средних значений скорости речи
5. Визуализация данных различными типами графиков
6. Интерпретация результатов
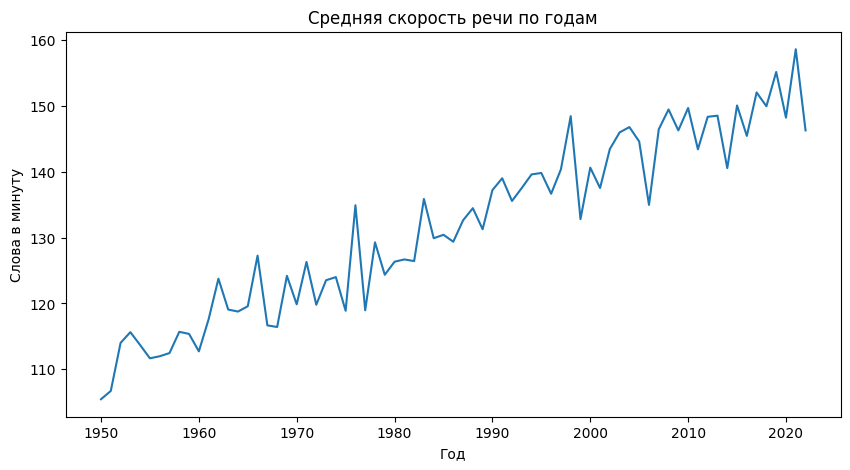
Средняя скорость речи по годам
plt.figure (figsize=(10,6)) plt.scatter (df['year'], df['wpm'], alpha=0.3) plt.xlabel («Год») plt.ylabel («Слова в минуту») plt.title («Связь года и скорости речи»)
Пояснение
«Диаграмма рассеяния показывает зависимость между годом высказывания и скоростью речи. В более ранние периоды значения скорости речи в среднем ниже, тогда как в современных выступлениях наблюдается смещение в сторону более высоких значений.»
Средняя скорость речи по форматам
avg_speed = df.groupby ('year')['wpm'].mean ()
plt.figure (figsize=(10,5)) plt.plot (avg_speed) plt.xlabel («Год») plt.ylabel («Слова в минуту») plt.title («Средняя скорость речи по годам»)
Пояснение
«Линейный график демонстрирует устойчивый рост средней скорости речи на протяжении нескольких десятилетий. Этот тренд может отражать ускорение темпа жизни, развитие медиа и изменение форматов публичной коммуникации.»
Скорость речи по десятилетиям
df.boxplot (column='wpm', by='decade', figsize=(10,5)) plt.xlabel («Десятилетие») plt.ylabel («Слова в минуту») plt.title («Скорость речи по десятилетиям»)
Пояснение
«Диаграмма размаха показывает рост медианных значений скорости речи от десятилетия к десятилетию. Также увеличивается разброс значений, что указывает на разнообразие речевых стратегий в более поздние периоды.»
plt.figure (figsize=(8,5)) plt.hist (df['wpm'], bins=20) plt.xlabel («Слова в минуту») plt.ylabel («Количество наблюдений») plt.title («Распределение скорости речи»)
Пояснение
«Гистограмма позволяет увидеть, в каком диапазоне чаще всего находится скорость речи. Основная масса значений сосредоточена в среднем диапазоне, что позволяет говорить о существовании условной нормы темпа речи.»
Выводы
Результаты анализа показывают, что скорость публичной речи со временем увеличивается. Это может быть связано с ускорением информационной среды, изменением форматов коммуникации и ростом плотности передаваемой информации.
Проект демонстрирует, как количественный анализ речи может использоваться для изучения культурных и социальных изменений.
Описание применения генеративной модели
В процессе работы над проектом использовалась генеративная модель ChatGPT (OpenAI). Модель применялась для консультаций по работе с Python и Pandas, структурированию анализа данных, а также для помощи в формулировке текстовых пояснений и выводов.
Искусственный интеллект использовался как вспомогательный инструмент обучения и не выполнял автоматический анализ данных.
Материалы проекта
Google Colab — анализ данных и построение визуализаций https://colab.research.google.com/
Pandas — библиотека Python для обработки и анализа данных https://pandas.pydata.org/
Matplotlib — библиотека Python для визуализации данных https://matplotlib.org/
ChatGPT (OpenAI) — текстовое сопровождение проекта https://openai.com/chatgpt



