
Аналитика интереса к популярному кино: Wikipedia Pageviews
Введение
В проекте я анализирую данные о просмотрах статей Википедии (Wikipedia Pageviews). Это открытая статистика посещаемости страниц, доступная через официальный API Wikimedia Pageviews, который позволяет получить число просмотров выбранной статьи по дням (daily pageviews) за заданный период.
Просмотры Википедии — это практичный показатель коллективного внимания: когда общество активно обсуждает событие, фильм, технологию или персону, люди массово идут читать справочную информацию, и это мгновенно отражается в динамике pageviews. Мне было интересно изучить, насколько быстро возникает всплеск, как долго держится внимание, и чем отличаются вирусные темы от тем, которые привлекают внимание стабильно.
Для исследования я выбрала набор статей на одну смысловую тему — крупные релизы в кино, чтобы сравнить разные траектории интереса в сопоставимых условиях.
Этапы работы
1. Выбор темы и постановка вопросов 2. Сбор данных: выгрузила дневные просмотры статей Википедии по выбранным фильмам через Wikimedia Pageviews API и собрала единый датасет. 3. Преобразовала даты, объединила данные в таблицу дата × фильм, задала окно анализа вокруг релизов и добавила переменную days_from_release. 4. Посчитала 7-дневное сглаживание (rolling mean), долю внимания между фильмами, агрегацию по месяцам, а также суммарные просмотры в первые 30 дней после релиза. 5. Построила набор графиков разных типов. 6. Привела графики к единому инфографическому стилю.
Графики
Я составила список крупных кинорелизов и сопоставила каждому релизу соответствующую статью Википедии, например Barbie_(film), Oppenheimer_(film), Dune: _Part_Two.
Для каждой статьи я запросила дневные просмотры через Wikimedia Pageviews API с параметрами:
project = en.wikipedia.org (единая версия для корректного сравнения), access = all-access (desktop+mobile), agent = user (только реальные пользователи), granularity = daily (дневная временная шкала).
Я зафиксировала период вокруг премьер: от ~90 дней до самого раннего релиза и до ~180 дней после самого позднего.
Дневные просмотры имеют сильные колебания (эффект выходных, новостей и т. п.), поэтому для каждого фильма рассчитано 7-дневное скользящее среднее (rolling mean). Это уменьшает шум и делает тренд визуально интерпретируемым.
Внимание пользователей на временной шкале
Сравнение внимания пользователей к релизу
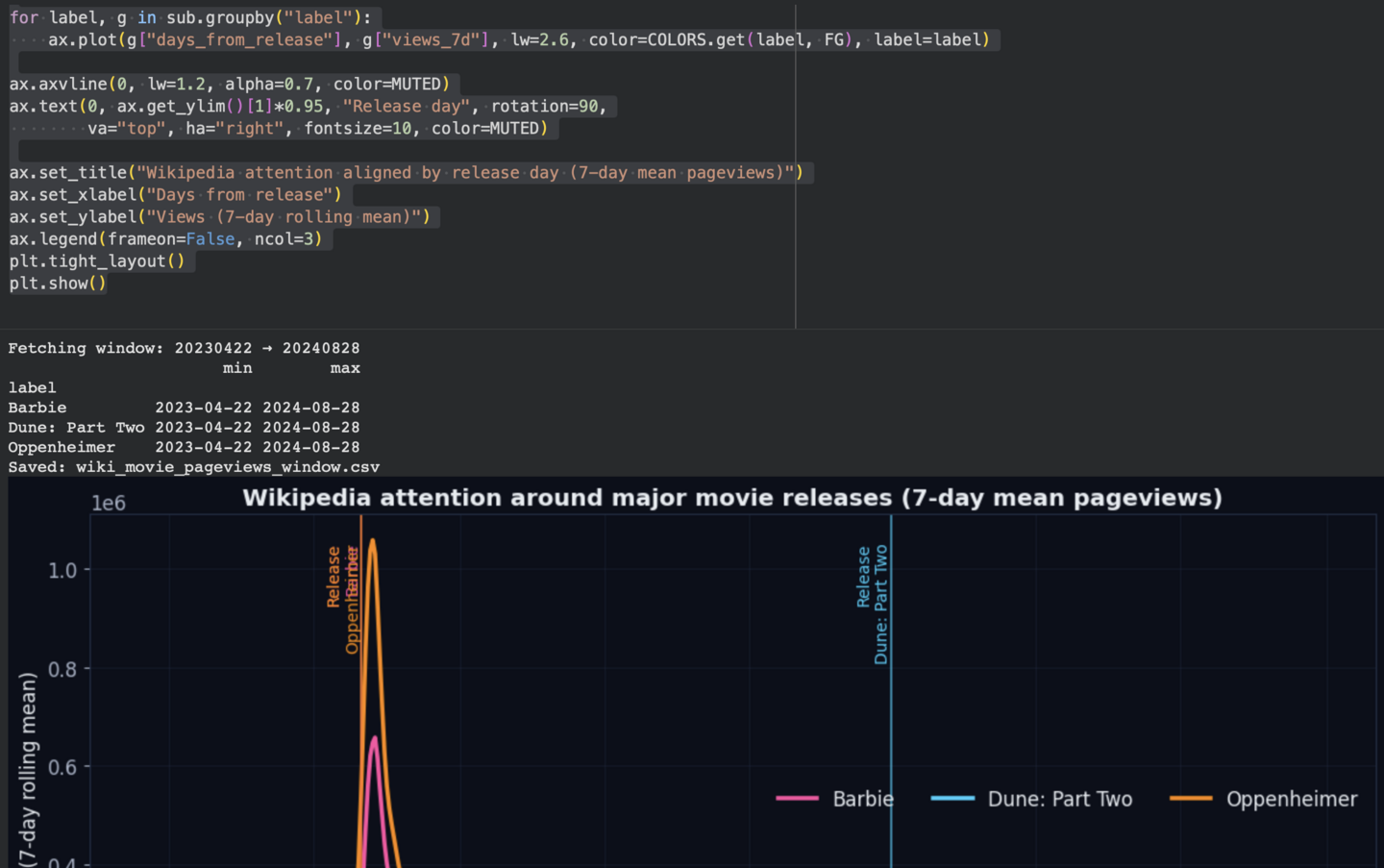
На первом графике данные показаны в календарном времени.
На втором графике все ряды выровнены по дню релиза (ось X — дни относительно премьеры).
Вокруг даты релиза у каждого фильма возникает резкий рост интереса к статье Википедии, после чего наблюдается постепенное затухание. Вертикальные линии помогают сопоставить основной пик с моментом премьеры, а остальная часть графика показывает хвост интереса после выхода фильма.
На календарном графике хорошо заметны дополнительные локальные подъёмы после премьеры. Вторичные волны обычно связаны с инфоповодами (награды, обсуждение, выход на цифровых платформах, новости об актерах).
Внимание к релизу не заканчивается строго на премьере, а может вспыхивать повторно.
Этот график показывает, как распределялось внимание аудитории между выбранными кинорелизами, измеренное через просмотры соответствующих статей Википедии. Для каждого дня я суммировала просмотры всех трех статей и посчитала долю каждого фильма.
На графике изображена 7-дневная средняя доля, чтобы сгладить дневные колебания и сделать динамику читаемой.
По оси Y всегда 0…1, а сумма слоёв в каждый день равна 1: это значит, что график показывает не абсолютный интерес, а кто доминировал среди выбранных фильмов в конкретный период. Когда оранжевый слой (Oppenheimer) занимает большую часть площади, это означает, что в эти дни его статья получала большую долю просмотров относительно Barbie и Dune. Увеличение голубого слоя (Dune: Part Two) весной 2024 показывает, что в этот период внимание внутри набора релизов сместилось в сторону Дюны. Розовый слой (Barbie) заметен сильнее в период лето–осень 2023: это отражает более высокую относительную долю интереса к Барби внутри выбранной тройки в те месяцы.
Тепловая карта внимания
Чтобы увидеть не отдельные дневные пики, а общую структуру интереса по месяцам, я агрегировала данные Wikimedia Pageviews из дневного уровня в месячный. Для каждого фильма я суммировала количество просмотров статьи Википедии по месяцам и визуализировала результат в виде теплокарты фильм × месяц.
Такой формат помогает быстро сравнить, в какие месяцы каждый релиз был в фокусе внимания, и как менялась интенсивность интереса после премьеры. Поскольку объёмы просмотров сильно различаются (у одних месяцев значения на порядок выше), для корректной визуальной шкалы применено логарифмическое преобразование log (1 + views).
Для Барби и Оппенгеймера максимум интенсивности приходится на лето 2023, что соответствует периоду премьеры и последующей волне интереса. Затем заметно постепенное остывание к осени–зиме. Для Дюны наиболее яркий период — весна 2024, то есть вокруг премьеры и первых недель после нее.
После пиков у всех фильмов интенсивность снижается и выходит на более ровный фон, это остаточный интерес к фильму, который остаётся после основной релизной волны.
Общее количество просмотров в первые 30 дней после релиза
После анализа динамики интереса во времени я свела данные к одной сравнимой метрике — эффект релиза. Для каждого фильма я посчитала суммарное количество просмотров статьи Википедии в первые 30 дней после премьеры. Такой показатель удобен тем, что он агрегирует силу первой волны интереса и позволяет сравнить релизы между собой в одинаковом временном окне, независимо от того, когда именно они вышли.
Наибольший релизный импакт у Оппенгеймера — 14 893 669 просмотров за первые 30 дней. Барби занимает второе место — 10 277 428 просмотров. Дюна — 5 774 360 просмотров, заметно ниже двух других в выбранном окне.
Метрика показывает именно внимание к статье, а не кассовые сборы или просмотры фильма; она отражает информационный спрос аудитории в период сразу после премьеры.
Заключение
В процессе работы я использовала генеративную языковую модель ChatGPT (OpenAI) как инструмент для поддержки программирования и оформления проекта. Модель применялась в среде Google Colab для написания и отладки кода на Python (Pandas/Matplotlib).
Генеративная модель использовалась как консультант по следующим задачам: — Проектирование пайплайна; — Отладка и интерпретация ошибок: объяснение причин ошибок (неправильный временной диапазон, особенности визуализации) и предложения по исправлению; — Рекомендации по настройке цветов и параметров Matplotlib, чтобы получить единый инфографический стиль.
Что было сделано вручную: — Выбор темы, фильмов и формулировка исследовательских вопросов; — Подбор дат релизов и выбор временного окна анализа; — Проверка логики расчетов и интерпретация результатов; — Итоговая сборка и оформление презентации (структура, выводы, визуальная подача).
Примеры промптов, которые использовались: «Как исправить график, если временной диапазон уехал в другой год?» «Сделай палитру: Barbie — розовый, Oppenheimer — оранжевый; оформи график в едином стиле.»
Результаты, предложенные моделью, проверялись вручную: корректность дат и диапазонов, соответствие данных источнику (Wikimedia Pageviews), а также соответствие визуализаций поставленным вопросам исследования. Генеративная модель не заменяла анализ; она использовалась для улучшения качества кода и оформления.



