
Идея проекта
Для изучения стиля художника и применения его в генерации изображений я выбрала свою любимую художницу Lola Dupre. Лола создаёт гигантские фотоколлажи из частичек того же изображения, что в итоге должно получиться. Она собирает разные необычные композиции и формы, а в особенности, она создаёт очень крутых котов, их я и решила использовать для обучения генеративной модели LOLA

Работа Lola Dupre
Исходные изображения
Фотоколлажи, Lola Dupre
Для обучения я выбрала 30 самых ярких картинок котов, каждую из которых я подогнала под размер 1:1 с разрешением 512×512 пикселей (для оптимизации работы)

Работа Lola Dupre
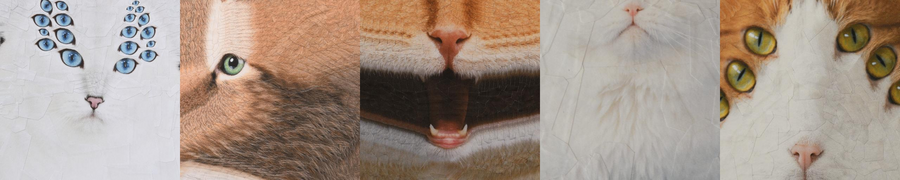
Серия итоговых фотоколлажей в стиле lola style
Изначально моей целью было создать серию домашних животных в стиле Lola Dupre. Я попробовала генерировать не только кошечек, но и собак. В целом, я довольна результатов и тем, как диффьюжен справилась с задачей с учетом того, что она обучалась только на композициях с кошечками. Кстати эти коллажи похожи на те, что делает Lola (она складывает не только котов, но и собак). Хотя, если смотреть на качество передачи эффекта наложения бумажки на бумажку, то тут оно страдает
Мои генерации, пробы на собаках; prompt: «LOLA style, a white dog with cute smile», «LOLA style, a blue dog with blue eyes»


1 — работа Lola Dupre; 2 — моя нейрособака
В итоге я решила сгенерировать серию кошечек. В начале я подстраивала параметры для того, чтобы стиль считывался. Эффект наложения бумажки на бумажку очень тонкий, поэтому приходилось долго менять настройки, отвечающие за детализацию, чтобы было видно, что это фотоколлаж (например, шаг с 25 до 50, checkpoint с 250 на 500 и lora_scale до 1). Также изначально я обучала модель на 20 картинках, что оказалось мало для передачи стиля (картинка с шестью собаками как раз первые попытки, prompt: «photo collage in LOLA style, dog»)


Не получившиеся кошки и собаки (слишком большое сглаживание, которое мешает проявлению текстуры); prompt: «LOLA style, a white cat and gray cat with cute smile and blue eyes»
Вот такая серия разных кошек, разных окрасок и цвет глаз у меня получилась. В процессе работы заметила, что в этом случае, чем проще промт, тем лучше результат
prompt: «LOLA style, orange cat»


prompt: «LOLA style, cat», «LOLA style, a white cat and gray cat with cute smile and blue eyes»
Также я пробовала промты с запросом двух животных, с чем нейронка справлялась чуть хуже (в силу того, что на исходных изображениях были только одиночные коты)


prompt: «LOLA style, a white dog and orange cat with cute smile and green eyes», «LOLA style, hugs a white dog with orange cat with cute smile and green eyes»
prompt: «LOLA style, cat»
prompt: «»


prompt: «LOLA style, a white cat and gray cat with cute smile and blue eyes», «LOLA style, a red-haired cat with blue eyes»
(вблизи) prompt: «LOLA style, a red-haired cat with blue eyes»
Процесс обучения
Вся работа по обучению генеративной модели была выполнена в Google Colab.
Перед началом работы я загружаю все библиотеки и обучающий скрипт с GitHub.
Шаг первый: установка библиотек
Далее я начинаю работать с датасетом LOLA_DUPRE. Импортирую его, загружаю нужные картинки в формате jpeg необходимого размера 1:1 и 512×512
Шаг второй: датасет
Шаг второй: датасет; превью
Далее с помощью кода я запускаю анализ каждого изображения и создание к нему уникального описания вместе с caption_prefix = «LOLA style, "
Импорт библиотек для создания описаний
Шаг третий: описания
После создания описаний и характеристик картинок я логинюсь на Hugging Face, чтобы потом сохранить там готовую модель
Шаг четвертый: Hugging Face
После всех предыдущих шагов я наконец запускаю обучение модели с ТОК «LOLA style». Для начала это базовые настройки с max_train_steps=500 и checkpointing_steps=250
Шаг пятый: обучение
Шаг пятый: обучение; проверка, что записалось в модели
Шаг шестой: связь с Hugging Face
Шаг шестой: связь с Hugging Face; сохраняю модель
Шаг седьмой: первые генерации; меняю шаг с 25 на 50
В процессе генерации я методом проб меняла настройки checkpointing, step и lora_scale, чтобы улучшить узнаваемость стиля и повысить детализированность изображения
Шаг седьмой: первые генерации; корректировка настроек, плохая передача стиля
Вывод
В конце обучения я чувствую, что довольна результатом. Поняла, что иногда излишние уточнения в промтах запутывают нейронку и она выдаёт не то, что ты ожидаешь. Также интересно, как от совсем небольшого сдвига, например, в шаге, меняется передача стиля. Мне кажется, серия котов удалась и диффюжен справилась
вот такие пироги



