
Топ 1000 фильмов по рейтингу IMDB
Для анализа я выбрал набор данных о фильмах с сайта Kaggle.
Эти данные представляют особую ценность, поскольку позволяют изучить эволюцию киноиндустрии и выявить, какие жанры были популярны в разные десятилетия.
Я решила использовать столбчатые диаграммы и сложенные графики, чтобы наглядно показать изменения в количестве фильмов по жанрам за годы. Эти типы графиков позволяют легко сравнивать данные между разными категориями и годами.
Виды графиков
- столбчатые диаграммы - линейные графики - круговые диаграммы - гистограммы - сложенные графики
ЭТАПЫ РАБОТЫ
import pandas as pd import matplotlib.pyplot as plt
Загрузка данных
data = pd.read_csv ('imdb_top_1000.csv')
Разделение жанров и создание списка всех жанров
data['Genre'] = data['Genre'].str.split (', ') # Разделяем жанры data = data.explode ('Genre') # Разбиваем строки с несколькими жанрами на отдельные строки
Подсчет количества фильмов по жанрам
genre_counts = data['Genre'].value_counts ()
Выбор топ-N жанров для визуализации (например, топ-10)
top_genres = genre_counts.head (10)
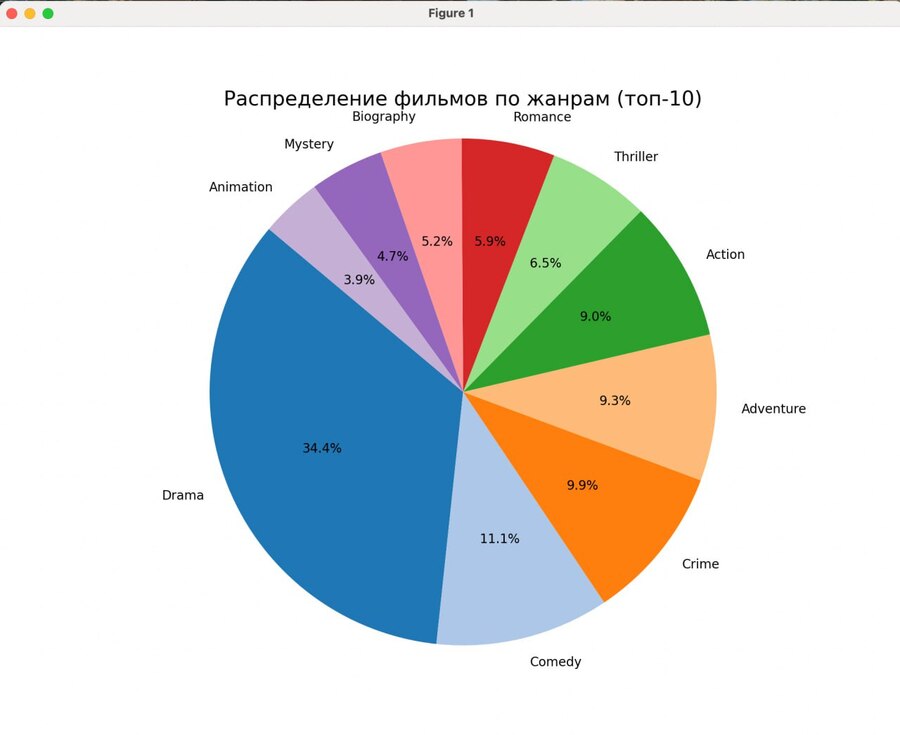
Построение круговой диаграммы
plt.figure (figsize=(10, 8)) plt.pie (top_genres, labels=top_genres.index, autopct='%1.1f%%', startangle=140, colors=plt.cm.tab20.colors) plt.title ('Распределение фильмов по жанрам (топ-10)', fontsize=16) plt.axis ('equal') # Чтобы диаграмма была круглой plt.show ()
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns
Топ-10 актеров по количеству фильмов
Загрузка данных
data = pd.read_csv ('imdb_top_1000.csv')
Сбор всех актеров в один список
actors = pd.concat ([data['Star1'], data['Star2'], data['Star3'], data['Star4']])
Подсчет количества фильмов по актерам
top_actors = actors.value_counts ().head (10)
Визуализация
plt.figure (figsize=(12, 6)) top_actors.plot (kind='bar', color='purple') plt.title ('Топ-10 актеров по количеству фильмов', fontsize=16) plt.xlabel ('Актер', fontsize=14) plt.ylabel ('Количество фильмов', fontsize=14) plt.xticks (rotation=45) plt.tight_layout () plt.show ()
import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns
Загрузка данных
data = pd.read_csv ('imdb_top_1000.csv')
Разделение жанров и создание списка всех жанров
genres = data['Genre'].str.split (', ', expand=True).stack ()
Подсчет количества фильмов по жанрам
genre_counts = genres.value_counts ()
Вывод топ-10 жанров
top_n = 10 # Показать топ-10 жанров top_genres = genre_counts.head (top_n)
Построение диаграммы с Seaborn
plt.figure (figsize=(12, 6)) sns.barplot (x=top_genres.index, y=top_genres.values, palette='viridis') plt.title (f’Топ-{top_n} жанров по количеству фильмов') plt.xlabel ('Жанр') plt.ylabel ('Количество фильмов') plt.xticks (rotation=45, ha='right') plt.tight_layout () plt.show ()
данные были взяты отсюда: https://www.kaggle.com/datasets/harshitshankhdhar/imdb-dataset-of-top-1000-movies-and-tv-shows/data



